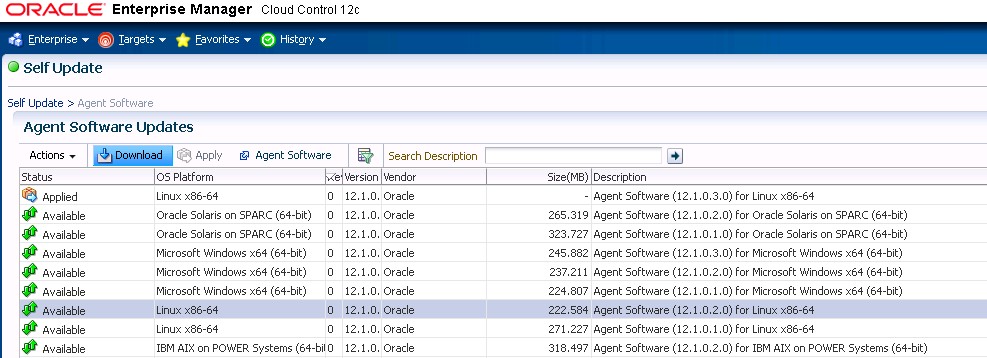
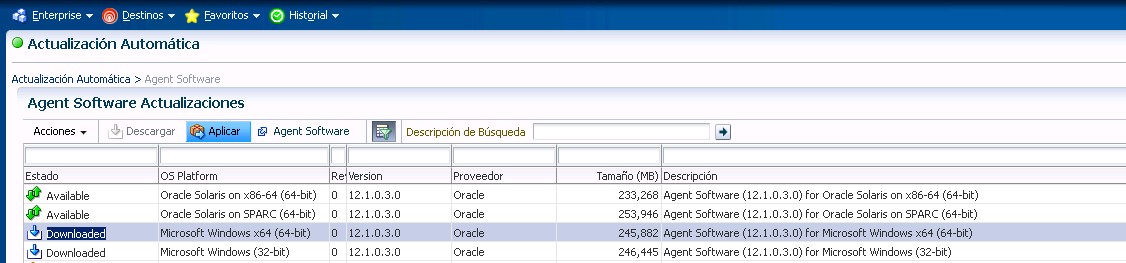
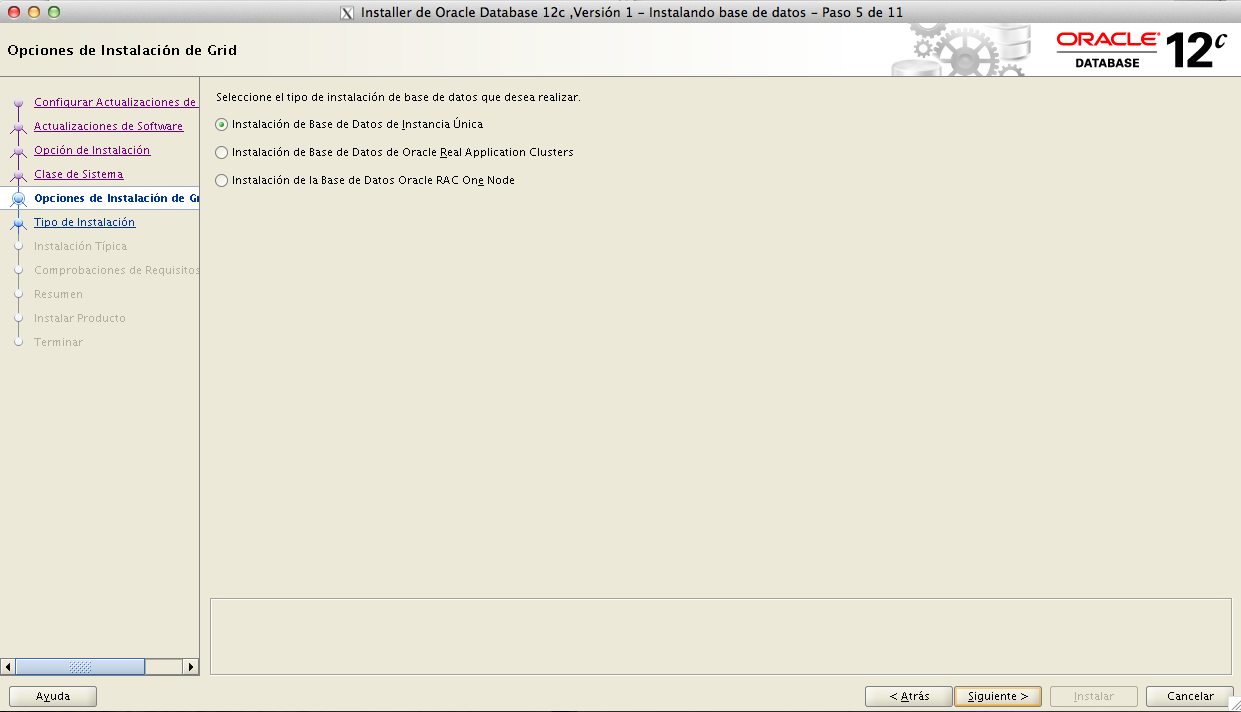
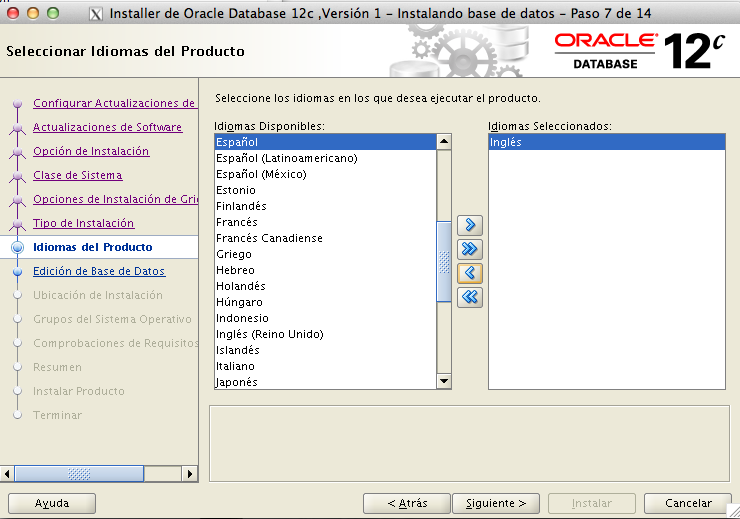
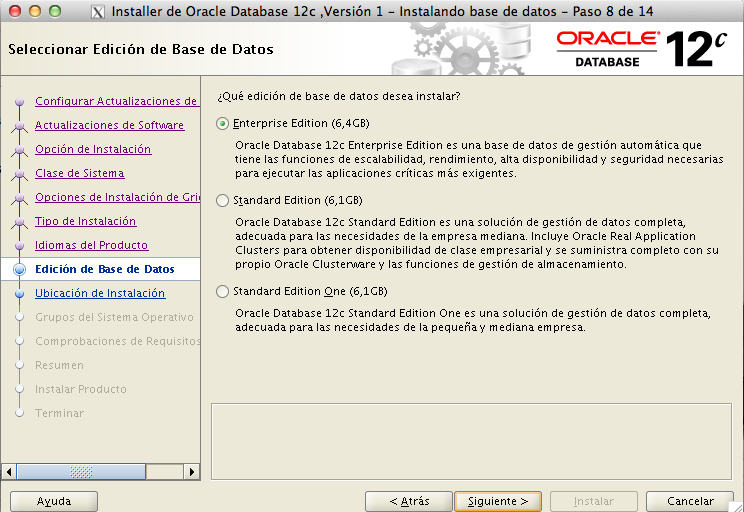
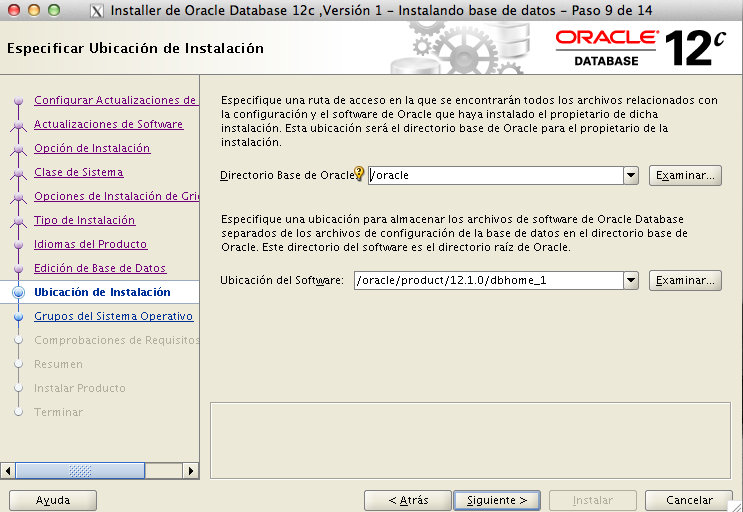
En la entrada anterior vimos como descargar los catálogos de agentes en el nuevo OEM12c, nuestro siguiente paso será el dar de alta un host para después poder dar de alta los elementos que lo contengan.
Algo que pude sorprender respecto de las anteriores versiones del oem es que, en esta version 12.1.0.3.0 del Enterprise Manager, los agentes no son programas cliente que te descargas e instalas en el servidor, son programas que se despliegan desde el OEM12c por ssh
En vista de esto,lo primero que se nos viene a la cabeza es ¿que hacemos con los windows?
Lo primero que tendremos que hacer es instalar un servidor de ssh para windows, en el mercado hay varios de ellos, sin embargo,y a pesar de que es de los que personalmente menos me gustan, yo solamente recomiendo la instalación de uno de ellos, el cygwin .
¿Por que de esta recomendación?
Por que es el que aconseja Oracle en su manual de instalación, y, ya que vamos a instalar un elemento extraño en un entorno windows, al menos, usemos el que está documentado y sobre el que vamos a tener soporte.
El proceso de descarga e instalacion de cygwin está perfectamente documentado en los pasos previos a la instalacion del oem12c para windows Install cygwin. Seguiremos ese enlace y crearemos un usuario con permisos de administración ( por ejemplo usuario oem)
Una vez lo tenemos instalado, lo primero que debemos de hacer es probarlo, para ello abriremos una conexión ssh con el servidor windows, comprobando que podemos logarnos en el sistema con ese usuario oem que hemos creado previamente. Hasta que este paso no este claro y en funcionamiento no podemos seguir con el despliegue del agente.
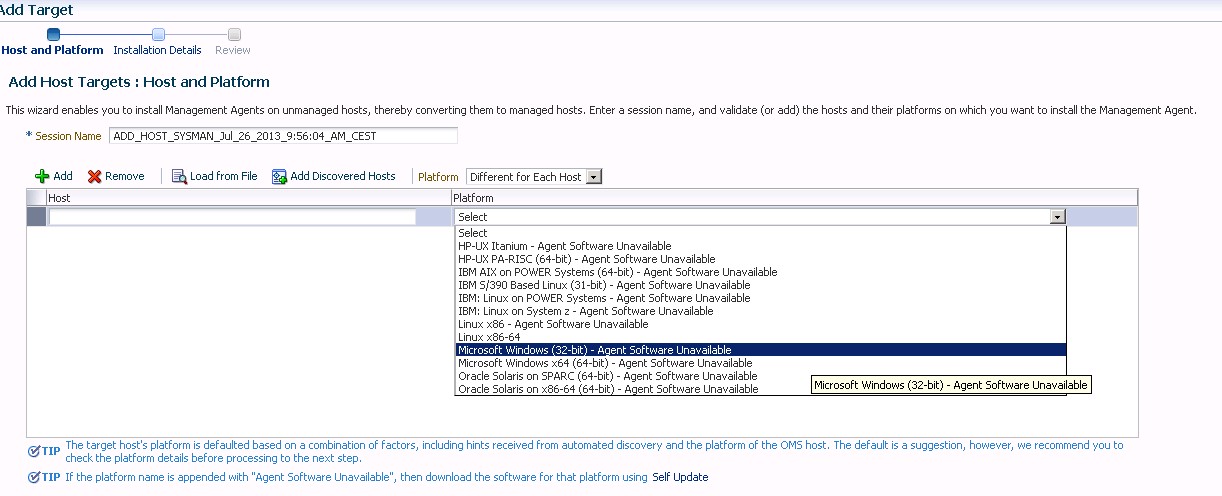
Lo primero que haremos es buscar el alta manual
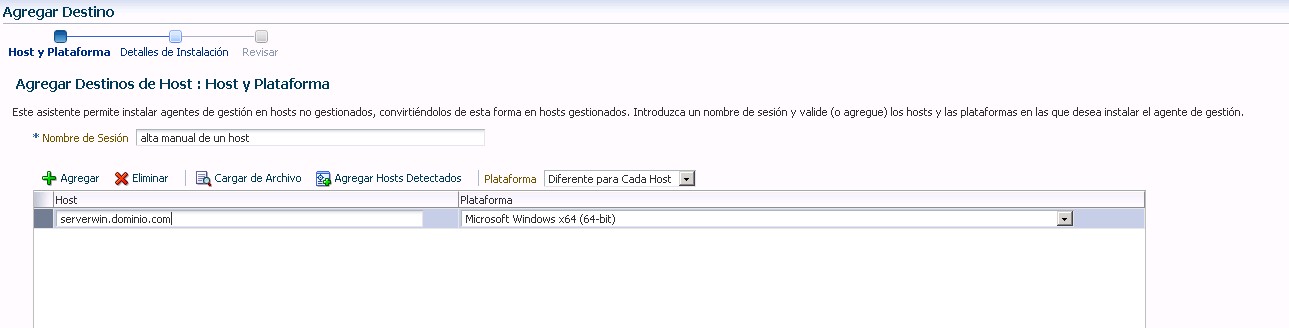
Tras eso llegamos a la ventana del directorio de instalación, a pesar de que la instalación se va a llevar a cabo mediante ssh y que el cygwin es capaz de ver las rutas de disco con path unix, la definición de directorios en esta pestaña debe de ser en modo windows, es decir c:\ d:\
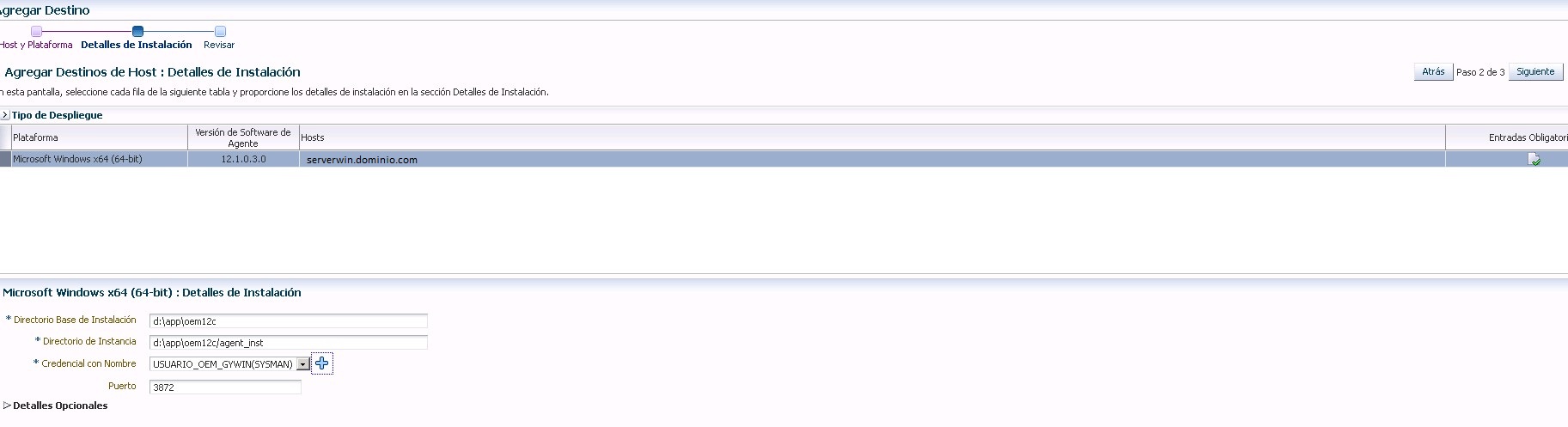
Una vez hemos decidido el lugar, tendremos que dar los datos de la conexión ssh, para esta conexión aconsejo el crear un usuario windows (por ejemplo OEM ) dentro del grupo DBA y hacer la equivalencia en el cygwin con ese usuario
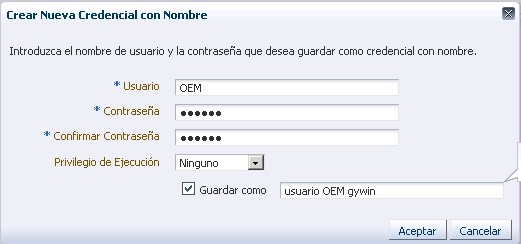
Tras esta pantalla llegamos a una ventana de trámite de confirmación de datos de despliegue de agente en la que le daremos a desplegar agente. Una vez le decimos que despliegue el agente, oem12c llevará a cabo una serie de comprobaciones en el host destino, estas comprobaciones son bastante completas
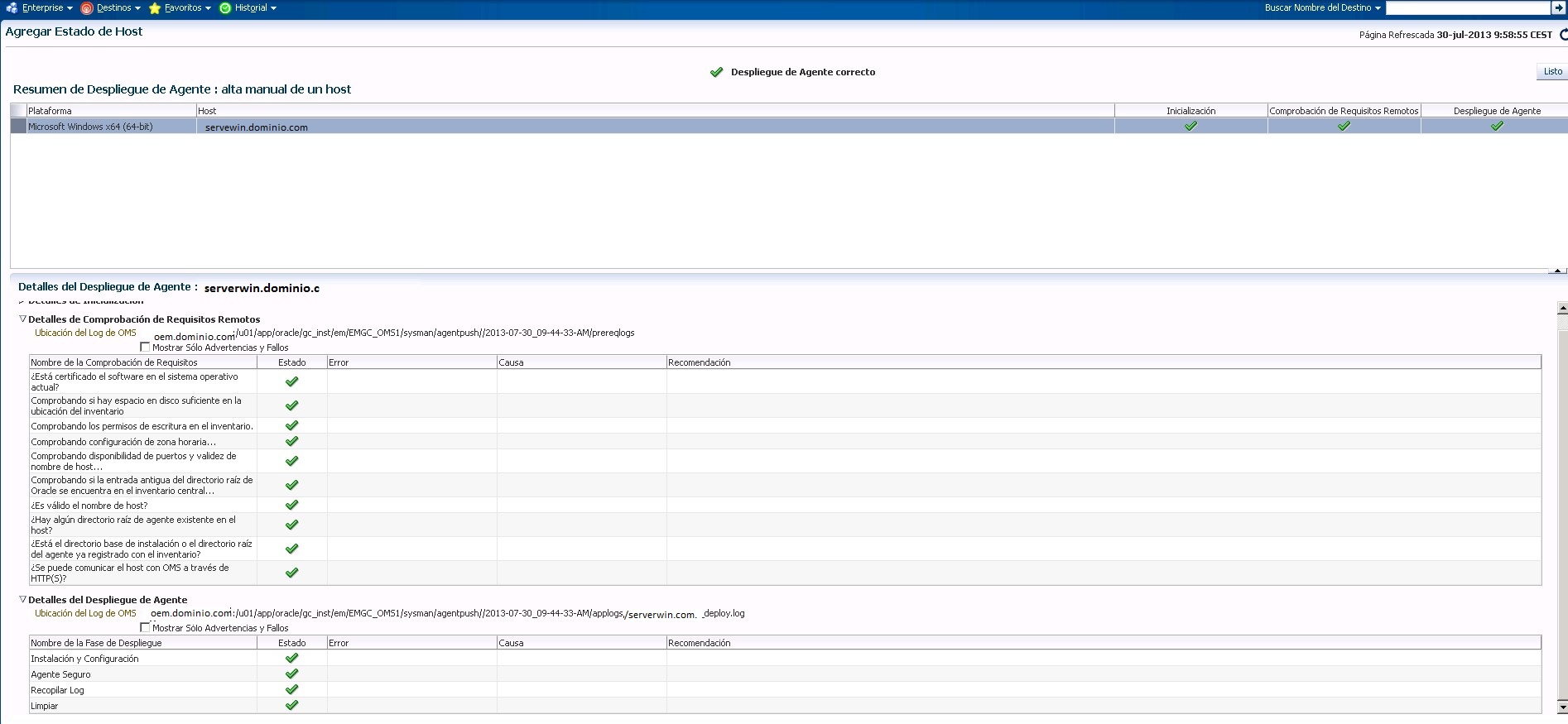
Una vez tengas el OK en todas las comprobaciones, la instalación es inmediata.
Como veis, la instalación de un agente de windows es prácticamente siguiente-> siguiente, la mayor dificultad es el asumir que esta se lleva a cabo mediante ssh y no mediante protocolos de Microsoft.