Una de las cosas que hay que llevar a cabo cuando se utiliza el Enterprise Manager de Oracle es el instalar/desisntalar los agentes.
Bien sea por que queremos actualizarlos, limpiar la máquina o simplemente por que decidimos hacerlo, tenemos que poder quitar los agentes de oracle.
Lo primero siempre será pararlo
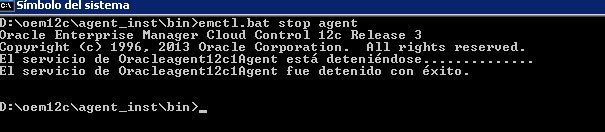
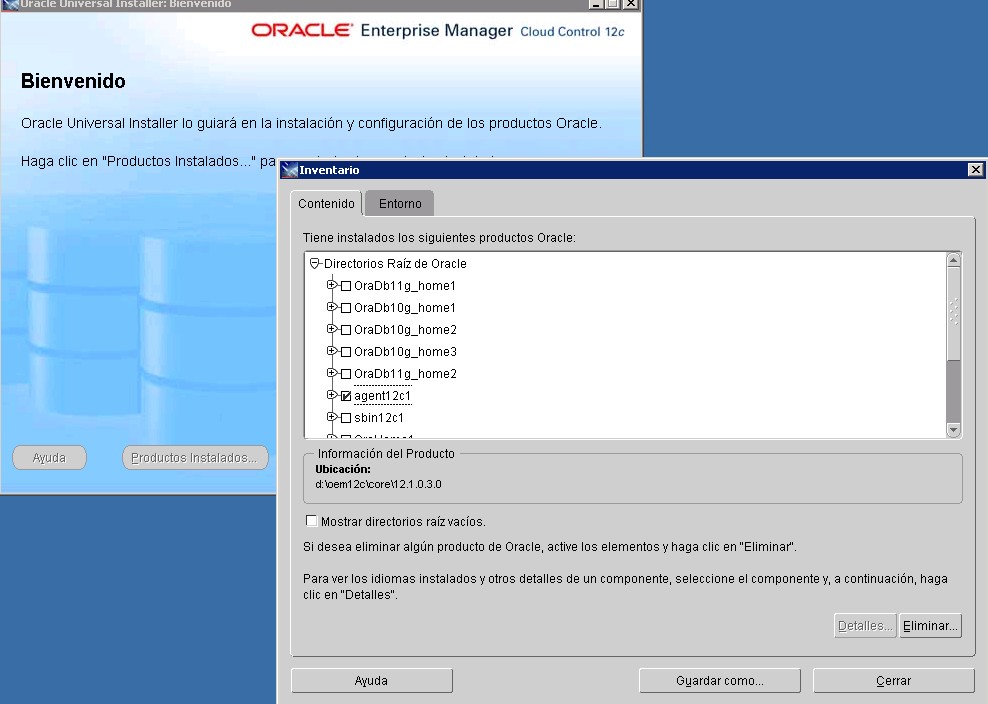
Si el agente se ha instalado de manera correcta, no deberíamos de tener muchos problemas para desinstalarlo, ya que debe de estar contenido en el inventario y deberíamos de poder eliminarlo sin problemas.
Por ejemplo, en el caso de un equipo windows, deberíamos de poder eliminarlo desde el propio oracle installer.
En el caso de un sistema Unix, el encontrar en instalador suele ser mas complicado, por lo que lo tendremos que parar a mano.
Una de las maneras mas sencillas de encontrarlo es mirar en el fichero
/etc/oragchomelist
/opt/app/oracle/product/oem12/agent12c/core/12.1.0.4.0:/opt/app/oracle/product/oem12/agent12c/agent_inst /opt/app/oracle/product/oem13/agent13c/agent_13.2.0.0.0:/opt/app/oracle/product/oem13/agent13c/agent_inst
Aqui podemos ver como tenemos los agentes de la version 12 y 13.
Para eliminar el de la 12 deberiamos de
1- Parar el agente
/opt/app/oracle/product/oem12/agent12c/agent_inst/bin emctl stop agent
2- mediante el comando AgentDeinstall.pl que nos eliminará la instalación del inventario y si se lo pedimos nos eliminará tambien el $AGENT_HOME
[server@OEM12c] export AGENT_HOME=/opt/app/oracle/product/12.1.0.3/oem12/
agent12c
core/12.1.0.4.0
[server@OEM12c] $AGENT_HOME/sysman/install/AgentDeinstall.pl -agentHome $AGENT_HOME
Agent Oracle Home: /opt/app/oracle/product/12.1.0.3/oem12/core/12.1.0.4.0
aentHome = /opt/app/oracle/product/12.1.0.3/oem12/core/12.1.0.4.0
NOTE: The agent base directory: /opt/app/oracle/product/12.1.0.3/oem12 will be removed after successful deinstallation of agent home.
DetachHome Command executed:/opt/app/oracle/product/12.1.0.3/oem12/core/12.1.0.4.0/oui/bin/runInstaller -detachHome -force -depHomesOnly -silent ORACLE_HOME=/opt/app/oracle/product/12.1.0.3/oem12/core/12.1.0.4.0 -waitForCompletion -invPtrLoc /opt/app/oracle/product/12.1.0.3/oem12/core/12.1.0.4.0/oraInst.loc
Starting Oracle Universal Installer...
Checking swap space: must be greater than 500 MB. Actual 53247 MB Passed
The inventory pointer is located at /opt/app/oracle/product/12.1.0.3/oem12/core/12.1.0.4.0/oraInst.loc
'DetachHome' was successful.
Starting Oracle Universal Installer...
Checking swap space: must be greater than 500 MB. Actual 53247 MB Passed
The inventory pointer is located at /opt/app/oracle/product/12.1.0.3/oem12/core/12.1.0.4.0/oraInst.loc
The Oracle home '/opt/app/oracle/product/12.1.0.3/oem12/sbin' could not be updated as it does not exist.
Deinstall Command executed:/opt/app/oracle/product/12.1.0.3/oem12/core/12.1.0.4.0/oui/bin/runInstaller -deinstall -silent "REMOVE_HOMES={/opt/app/oracle/product/12.1.0.3/oem12/core/12.1.0.4.0}" -waitForCompletion -removeAllFiles -invPtrLoc /opt/app/oracle/product/12.1.0.3/oem12/core/12.1.0.4.0/oraInst.loc
Starting Oracle Universal Installer...
Checking swap space: must be greater than 500 MB. Actual 53247 MB Passed
Preparing to launch Oracle Universal Installer from /tmp/OraInstall2018-03-21_09-43-48AM. Please wait ...Oracle Universal Installer, Version 11.1.0.12.0 Production
Copyright (C) 1999, 2014, Oracle. All rights reserved.
Starting deinstall
Deinstall in progress (Thursday, March 21, 2018 9:43:56 AM CET)
Configuration assistant "Agent Deinstall Assistant" succeeded
............................................................... 100%
Done.
Deinstall successful
End of install phases.(Thursday, March 21, 2018 9:44:10 AM CET)
End of deinstallations
Please check '/opt/app/oraInventory/logs/silentInstall2018-03-21_09-43-48AM.log' for more details.
NOTE: The targets monitored by this Management Agent will not be deleted in the Enterprise Manager Repository by this deinstall script. Make sure to delete the targets manually from the Cloud Control Console for a successful deinstallation.
Deinstall successful
Como veis, no es algo a lo que debamos temer.
La información completa de como llevarlo a cabo, como siempre en la documentación de Oracle
http://docs.oracle.com/cd/E24628_01/install.121/e24089/deinstall_agent.htm#CBBJEHDI