
Hoy vamos a ver una entrada referente a SQLserver.
Habitualmente cuando se habla de ajuste de índices todos tendemos a pensar en la creación de los mismos, sin embargo,la revisión del uso de los índices y la eliminación de los índices que no se usan es una tarea de administración muy recomendable, tanto por el aprovechamiento del espacio en disco como por la mejora que conlleva sobre la entrada salida (recordemos que cada inserción en una tabla indexada conlleva la actualización de los índices asociados).
SQLServer tiene desde la versión 2005 una tabla llamada SYS.DM_DB_INDEX_USAGE_STATS en la cual podemos hacer un seguimiento del uso de los indices de las bases de datos.
Los campos con los que nos quedaremos de esta tabla son
- user_seeks: Número de consultas de búsqueda realizadas por el usuario.
- user_scans: Número de consultas de recorrido realizadas por el usuario.
- user_lookups: Número de búsquedas de marcadores realizadas por consultas de usuario.
- user_updates: Número de consultas de actualización realizadas por el usuario.
Así pues, lo que debemos de buscar son índices sobre los que no hayamos hecho seeks,scans o lookups.
Esto lo podemos hacer con la consulta:
SELECT OBJECT_NAME(S.[OBJECT_ID]) AS [OBJECT NAME],
I.[NAME] AS [INDEX NAME],
USER_SEEKS,
USER_SCANS,
USER_LOOKUPS,
USER_UPDATES
FROM SYS.DM_DB_INDEX_USAGE_STATS AS S
INNER JOIN SYS.INDEXES AS I ON I.[OBJECT_ID] = S.[OBJECT_ID] AND I.INDEX_ID = S.INDEX_ID
WHERE OBJECTPROPERTY(S.[OBJECT_ID],’IsUserTable’) = 1
AND S.database_id = DB_ID()
AND user_seeks=0
AND user_scans=0
AND user_lookups=0
ORDER by user_updates DESC;
GO
Esta consulta nos devuelve algo similar a :
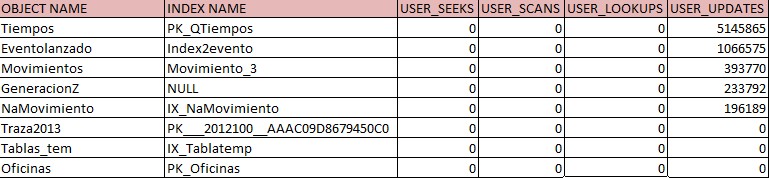
Donde podemos ver como hay índices que se encuentran sobre tablas muy actualizadas ( valor de user_updates muy alto) pero que no tienen uso en búsquedas, y otros que se encuentran sobre tablas que ni siquiera se actualizan.
Ahora nuestro trabajo es explorar esas tablas y ver si estos índices tienen sentido para, en caso de no tenerlo eliminarlos del sistema.