Repasando las entradas anteriores he podido comprobar como , tas la entrada de RAC I Preparativos no teníamos las siguientes entradas de instalación del RAC, así pues, vamos a hacer de nuevo la instalación para dejarla documentada.
Partimos de la base de la configuración de entorno y máquinas del post RAC I Preparativos
Como recordatorio rápido tenemos que los directorios a utilizar serán:
- GI_HOME=/oracle/11.2.0/grid
- ORACLE_BASE=/oracle/app/grid
grid
Y la configuración de red de los servidores será
# Direcciones para nuestros equipos
# HOST y publica eth0
10.0.2.2 exodar.pamplona.name exodar
10.0.2.3 rac1.pamplona.name rac1
10.0.2.4 rac2.pamplona.name rac2
10.0.2.5 rac3.pamplona.name rac3
10.0.2.6 rac4.pamplona.name rac4
10.0.2.24 plantilla.pamplona.name plantilla
#Virtual Eth1 direcciones de la red sobre la que se da el servicio
192.168.1.1 exodar-vip.pamplona.name exodar-vip
192.168.1.2 rac1-vip.pamplona.name rac1-vip
192.168.1.3 rac2-vip.pamplona.name rac2-vip
192.168.1.4 rac3-vip.pamplona.name rac3-vip
192.168.1.5 rac4-vip.pamplona.name rac4-vip
192.168.1.24 plantilla-vip.pamplona.name plantilla-vip
#ScaN comentadas ya que estan dada de alta en round robin dns
# estas son las verdaderas direcciones de servicio
#192.168.1.20 ractest.pamplona.name ractest
#192.168.1.21 ractest.pamplona.name ractest
#192.168.1.22 ractest.pamplona.name ractest
#Private ETH2 red privada de los nodos
192.168.2.1 exodar-priv.pamplona.name exodar-priv
192.168.2.2 rac1-priv.pamplona.name rac1-priv
192.168.2.3 rac2-priv.pamplona.name rac2-priv
192.168.2.4 rac3-priv.pamplona.name rac3-priv
192.168.2.5 rac4-priv.pamplona.name rac4-priv
192.168.2.24 plantilla-priv.pamplona.name plantilla-priv
Así pues, lanzamos la instalación del grid control:
En nuestro caso omitiremos la información de soporte, en el caso de una instalación real de RAC es muy recomendable el incluirla ya que facilitará mucho el uso del área de soporte así como la descarga de los últimos parches para llevar a cabo la instalación de la ultima versión disponible.
En la siguiente pantalla indicaremos que queremos instalar la versión del grid infraestructure que aplica a un cluster

Nosotros elegiremos la instalación avanzada para poder afinar mas las opciones de instalación.

En este punto comenzamos con la instalación específica del rac.
Aquí tendremos que introducir las direcciones de servicio y privadas del RAC.
Hemos de tener en cuenta que, nosotros ya teníamos comprobado y solucionado el tema de la conexión ssh entre los nodos, en caso de no estar claro ese tema, podremos comprobarlo desde la opción conectividad ssh
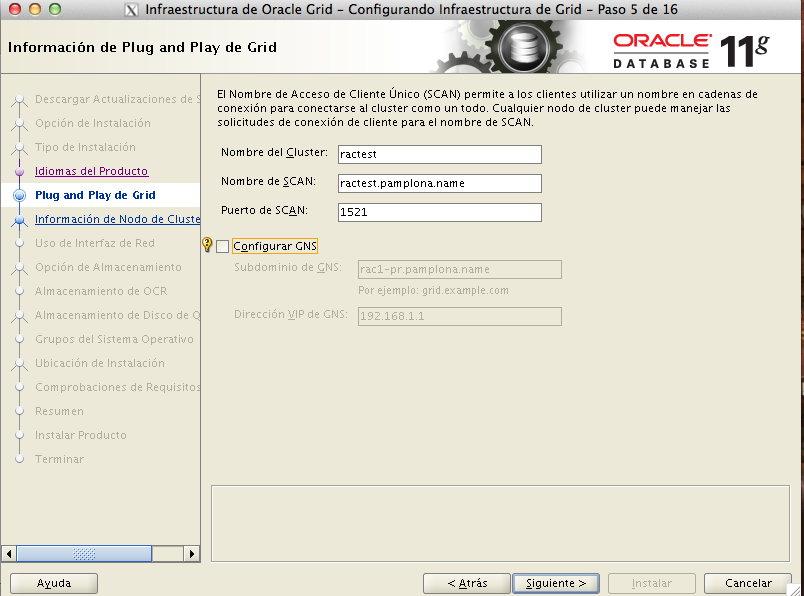
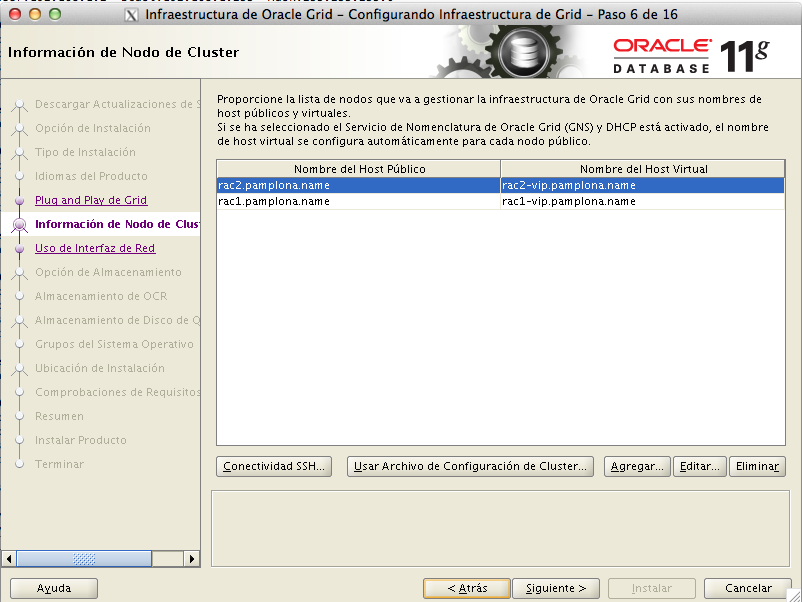
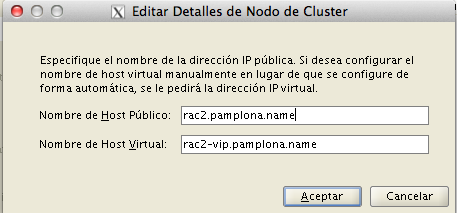
Si la configuración de las tarjetas con los nombres es correcta, pasamos a la pantalla en la que indicamos cual van a ser las direcciones de red.
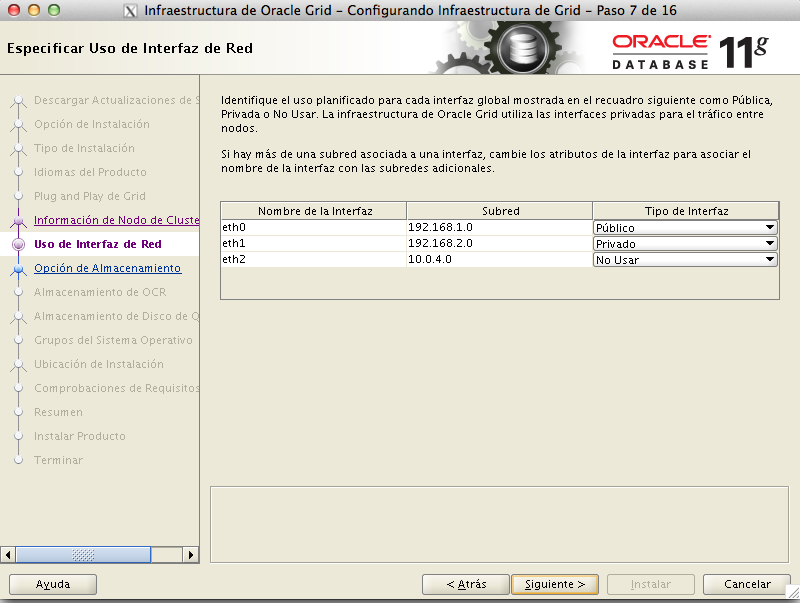
Como las traducciones las carga el diablo,vamos a detallar unpoco que es cada cosa:
- privada:van a ser las interfaces de interconexión del rac, esta debe de ser una conexión dedicada para la sincronización de las caches.
- públicaEs las interfaces vip que serán sobre las que posteriormente Oracle levantará las interfaces de scan
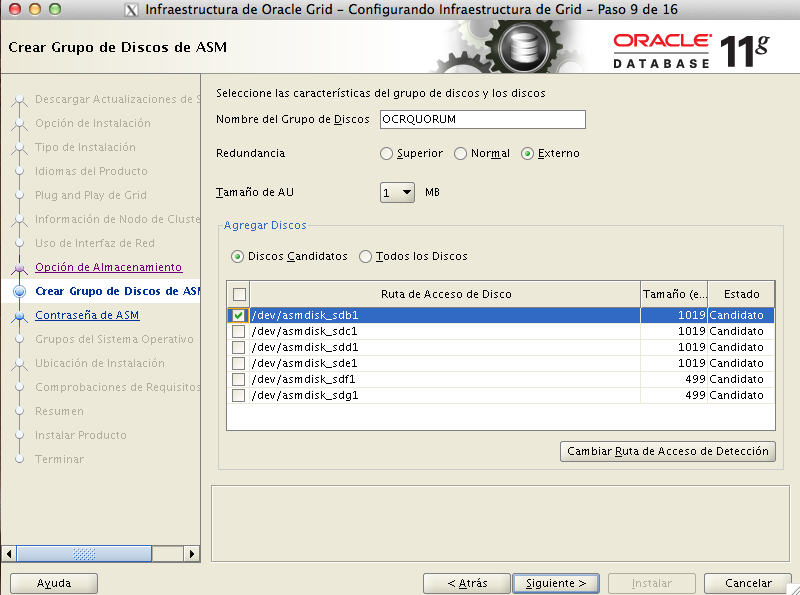
La version 11.2 del Grid nos permite tener el OCR y el Quorum en un disco en ASM, nosotros vamos a elegir este tipo de instalacion

Estamos en el momento en el que ASM nos muestra los discos disponibles, en nuestro caso lo hacemos mediante asmlib ( ver RAC I Preparativos ) , en la imagen tenemos que vamos a crear el grupo de discos OCRQUORUM y vamos a usar 1 disco de los que tenemos con la redundancia EXTERNAL.
En un entorno de producción real, será más aconsejable el uso de varios discos de 1 Gb con redundancia SUPERIOR.
Que el nombre del grupo de datos sea distinto a DATA (por defecto), llamándose OCRQUORUM no es un standard o buena práctica de Oracle, sino una modificación mía para que sirva para distinguirlo fácilmente del nombre del diskgroup que usaré en las bases de datos
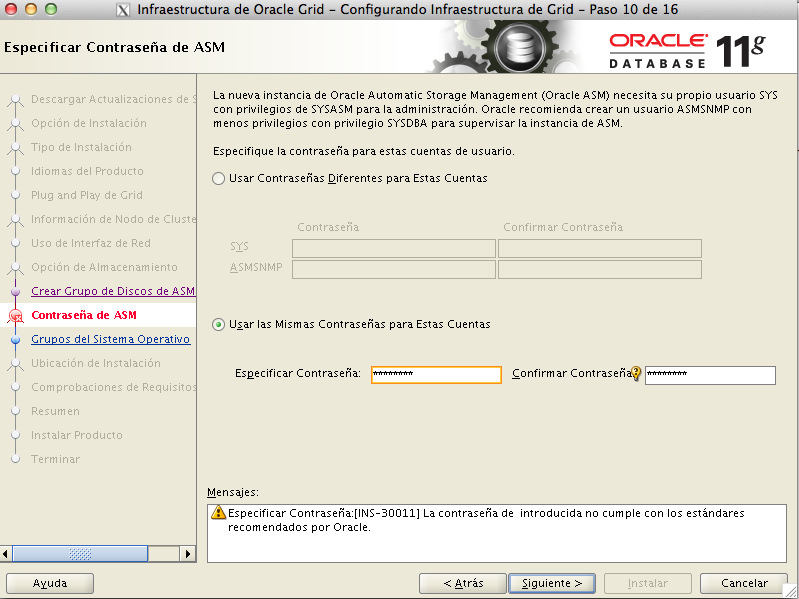
El IPMI podríamos decir que es lo que tradicionalmente se ha llamado fencing , para tener mas infiormación del mismo podemos mirar en la documentación de Oracle Configuring IPMI for Failure Isolation, en nuestro caso, no lo vamos a activar.

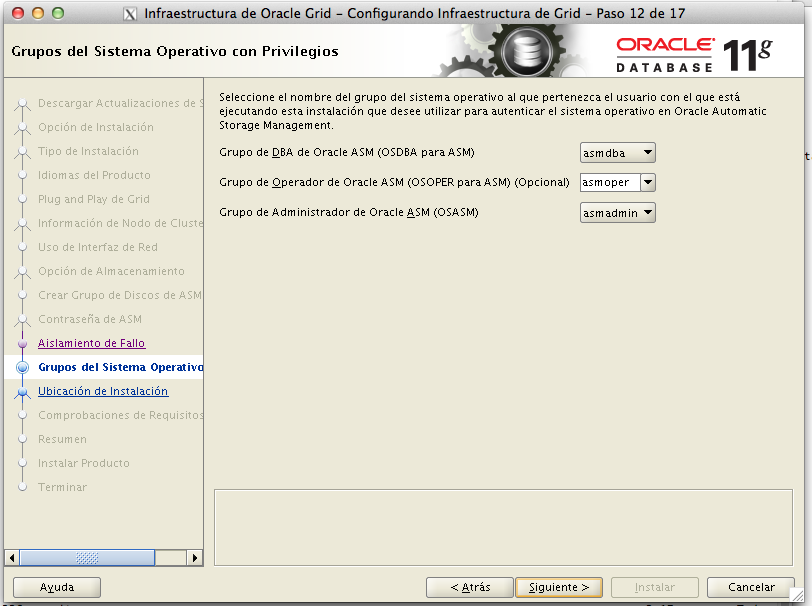
Indicamos los directorios que teníamos planificados

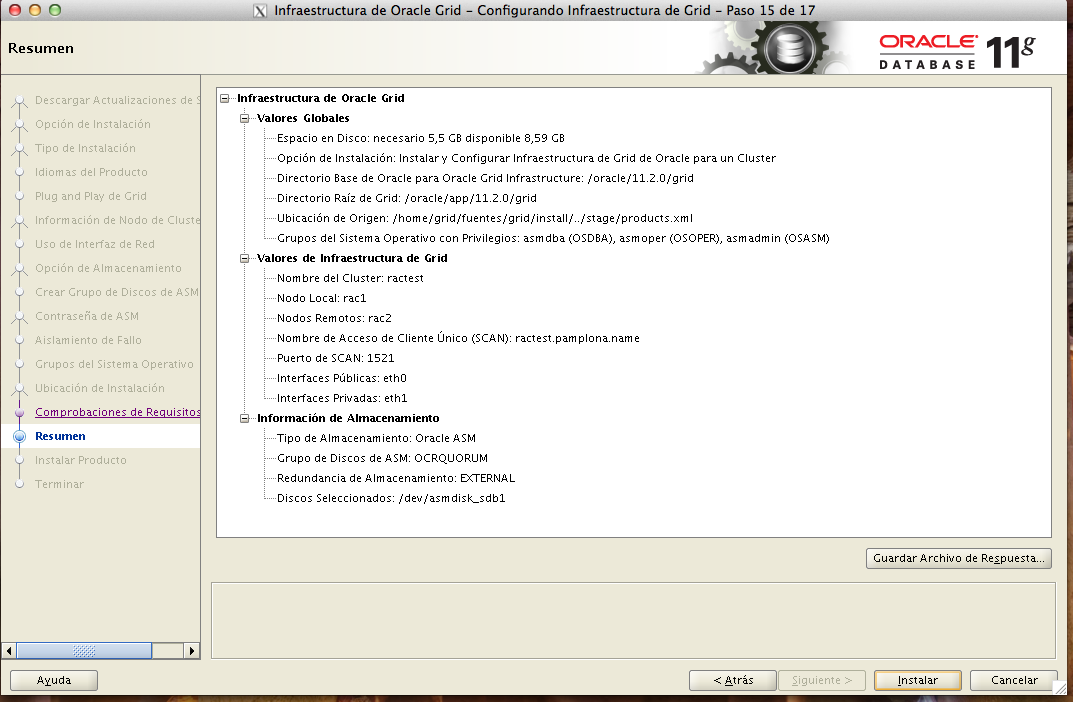
Finalmente, vemos las opciones y el resumen
Y la tipica ventana de ejecución de los comandos como root.
Aquí hemos de ser pacientes y ejecutar los scripts en orden, primero siempre en el nodo en el que estamos llevando a cabo la instalacón, y, solamente cuando hallan acabado de manera correcta ejecutarlos en el otro nodo

Tras esto, continuamos con la instalación dando a «siguiente» hasta que finalice.
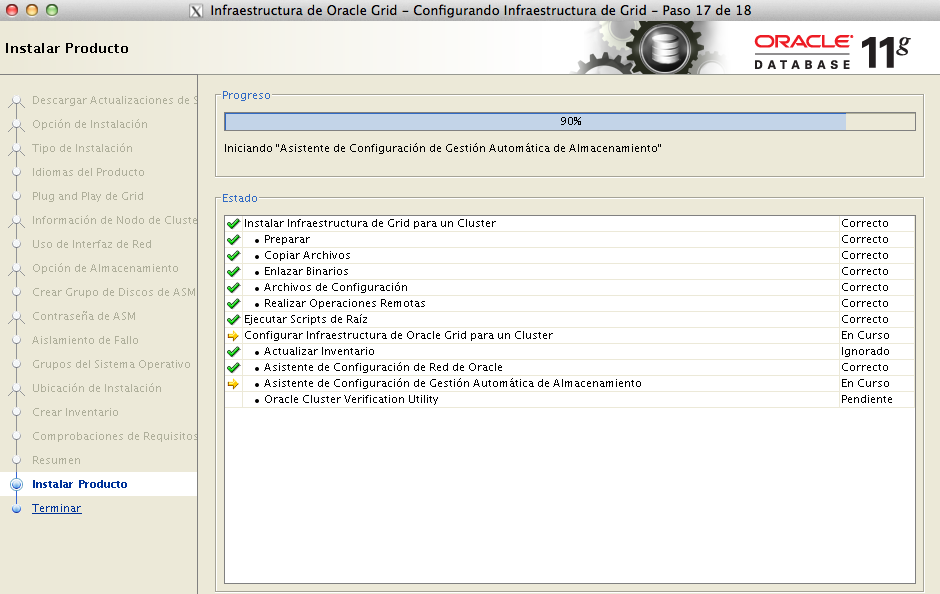
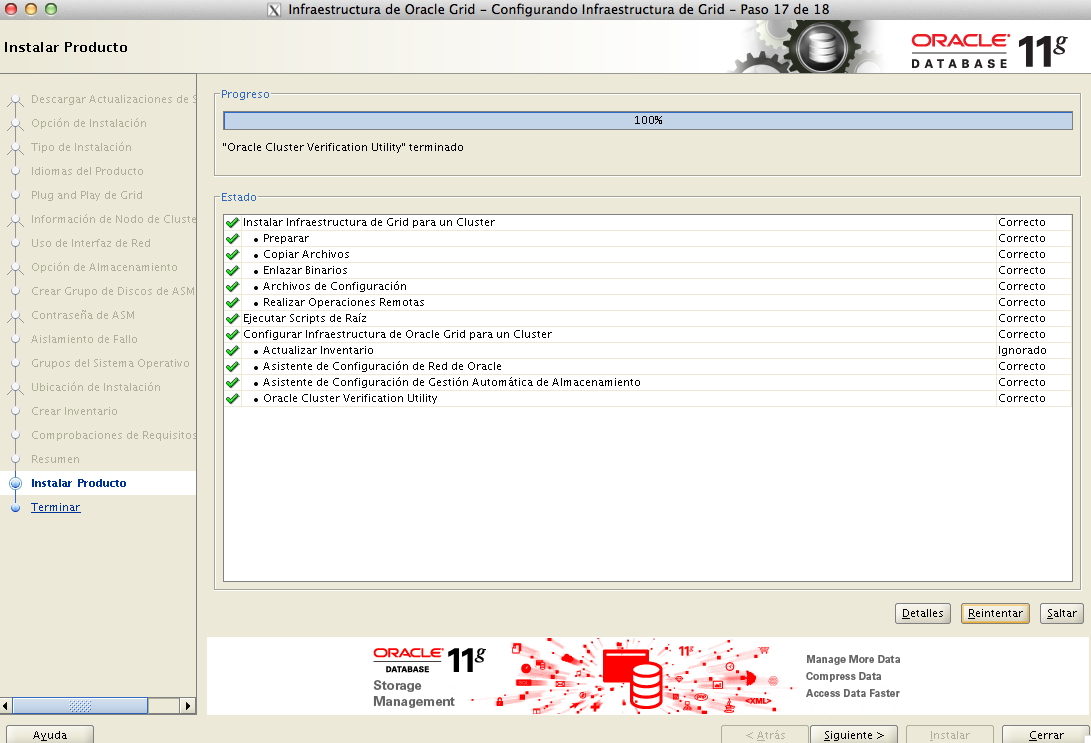
La instalación del Grid Infraestructure no es (desde mi punto de vista) algo muy limpio, y , tiene bastantes papeletas de fallar en algún punto, por lo que, es muy recomendable el tener a mano las notas específicas de soporte Oracle que nos ayudarán a solucionar estos problemas.
Estas notas son:

+12.04.29.png)
+12.06.29.png)
+12.12.37.png)