
Hoy vamos a ver como resolver errores ORA-24247 en la version 11g . Aunque desde aquí siempre hemos mantenido (y mantendremos) que la base de datos no debería ser la responsable de enviar correos o conectarse a «vete a saber donde» hay entornos en los que nos vemos obligados a ello.
¿Que ocurre si nos encontramos con un error de este tipo ?
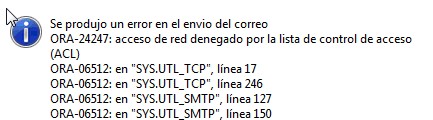
ERROR at line 1: ORA-24247: network access denied by access control list (ACL) ORA-06512: at "SYS.UTL_TCP", line 17 ORA-06512: at "SYS.UTL_TCP", line 246 ORA-06512: at "SYS.UTL_SMTP", line 115 ORA-06512: at "SYS.UTL_SMTP", line 138 ORA-06512: at "XXX", line 36 ORA-06512: at line 1
Este error es debido a que no contamos con una ACl para el servicio de red, las ACLs son un elemento nuevo de Oracle 11g (11.1.0.6) que establece un filtrado mas detallado (fine-grained access) y que controla el acceso a algunos paquetes como el UTL_SMTP o el UTL_HTTP.
¿como lo solicionamos?
Sencillamente tenemos que crear una ACL que nos permita acceder al puerto 25 de nuestro servidor de correo.
En este caso lo haremos para
- SMTP Server 127.0.0.1 (localhost de la BBDD)
- Puerto 25 ( puerto estandard de correo)
- usuarios Usuario1 y usuario2
Así pues , ejecutaremos :
begin --creamos la ACL DBMS_NETWORK_ACL_ADMIN.CREATE_ACL (acl => 'send_mail.xml', description => ' send_mail ACL', principal => 'USUARIO1', is_grant => true, privilege => 'connect'); -- Asignamos privilegios al usuario elegido DBMS_NETWORK_ACL_ADMIN.ADD_PRIVILEGE( acl => 'send_mail.xml', principal => 'USUARIO1', is_grant => true, privilege => 'connect'); DBMS_NETWORK_ACL_ADMIN.ADD_PRIVILEGE( acl => 'send_mail.xml', principal => 'USUARIO1', is_grant => true, privilege => 'resolve'); -- Asignamos provilegios al usuario elegido DBMS_NETWORK_ACL_ADMIN.ADD_PRIVILEGE( acl => 'send_mail.xml', principal => 'USUARIO2', is_grant => true, privilege => 'connect'); --Asignamos recursos dbms_network_acl_admin.assign_acl ( acl => 'send_mail.xm', host => '127.0.0.1', lower_port => 25, upper_port => 25); END; / COMMIT;
Si queremos ver las ACL creadas
SELECT * FROM dba_network_acls;
Y los privilegios de cada una de ellas
SELECT acl
,principal
,privilege
,is_grant
,invert
,start_date
,end_date
FROM dba_network_acl_privileges;
Como siempre , mas información en oracle en las notas:
- Información del paquete DBMS_NETWORK_ACL_ADMIN
- Doc ID 557070.1ORA-24247 Trying To Send Email Using UTL_SMTP from 11gR1 (11.1.0.6) or higher
- Doc ID 1137673.1 Master Note For PL/SQL UTL_SMTP and UTL_MAIL Packages